Padrões de codificação de caracteres
Uma codificação de caracteres é um padrão de relacionamento entre um conjunto de caracteres com um conjunto de outra coisa, como por exemplo números ou pulsos elétricos com o objetivo de facilitar o armazenamento de texto em computadores e sua transmissão através de redes de telecomunicação.
Exemplos comuns são o código morse que codifica as letras do alfabeto latino e os numerais como sequências de pulsos elétricos de longa e curta duração e também o ASCII que codifica os mesmos grafemas do código morse além de outros símbolos através de números inteiros e da representação binária em sete bits destes mesmos números.
Convencionalmente, conjunto de caracteres
e codificação de caracteres eram considerados sinónimos, já que o mesmo
nome poderia especificar tanto quais caracteres estão disponíveis e
como eles foram codificados em um fluxo de unidades de código
(normalmente com um único caractere por unidade de código). No entanto, o
Unicode
afastou essa idéia, separando a idéia de numerar uma série de
caracteres de codificar esses caracteres em um fluxo de unidades de
código. Para manter as nomenclaturas históricas e os sistemas baseados
nelas, usa-se o termo charset para se referir a uma codificação de caracteres.
Tabela de código ASCII e de código Unicode
Tabela de código ASCII
ASCII (American Standard Code for Information Interchange) é uma codificação de caracteres de sete bits. Cada sequencia de códigos na tabela ASCII corresponde a um caracter, representados pelos 8 bits (equivalente a um byte),
sendo que o oitavo bit (da direita para a esquerda) serve como um bit
de paridade, utilizado para detecção de erro. Os códigos ASCII
representam texto em computadores, equipamentos de comunicação, entre
outros dispositivos que trabalham com texto. Desenvolvida a partir de 1960, grande parte das codificações de caracteres modernas a herdaram como base.
A codificação define 128 caracteres, preenchendo completamente os sete bits disponíveis em 27=128 sequências possíveis. Desses, 33 não são imprimíveis, como caracteres de controle
atualmente não utilizáveis para edição de texto, porém amplamente
utilizados em dispositivos de comunicação, que afetam o processamento do
texto.
{kind=link}
 |
| Tabela ASCII |
Tabela de código UNICODE
Unicode é um padrão que permite aos computadores representar e manipular, de forma consistente, texto de qualquer sistema de escrita existente. O padrão consiste de pouco mais de 107 mil caracteres , um conjunto de diagramas de códigos para referência visual, uma metodologia para codificação e um conjunto de codificações padrões de caracteres, uma enumeração de propriedades de caracteres como caixa alta e caixa baixa, um conjunto de arquivos de computador com dados de referência, além de regras para normalização, decomposição, ordenação alfabética e renderização.
 |
| Tabela UNICODE |
Exemplos de conversão para código ASCII
Exemplo 1:
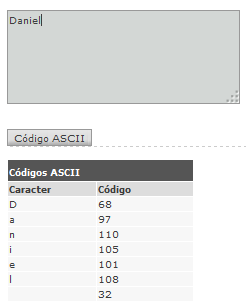
Exemplo 2:

Exemplos utilizando a ferramenta ASCII GENERATION
Exemplo 1:




Exemplos de conversão de imagens em código ASCII
Exemplo 1:
 |
| Imagem original |
 | |||||||
| Imagem convertida |
Exemplo 2:
{kind=link}
 |
| Imagem real Imagem convertida |
Fonte: http://www.glassgiant.com/ascii/
{kind=link}
Sem comentários:
Enviar um comentário